MemCraft
项目是什么
MemCraft 是一个面向长篇叙事文本的角色记忆数据构建系统。给定一篇小说、传记或剧本,以及一个目标角色名,它会通过一条可审查、可回退的分步流水线,从原文中抽取该角色的人生轨迹,并将其转换为结构化事件和第一人称记忆文本。
这个项目的想法来自我在实习期间参与的一个学术项目。当时我在做 HEART-Bench——一个衡量 Agent 长记忆信息召回率和角色一致性的评测体系,与上海交通大学和华南师范大学合作,目前已投稿 NeurIPS。在那个项目里,我深度参与了评测方案设计和数据集复核,也因此接触到了上交大团队构建角色记忆数据的方式。我发现,高质量的角色记忆数据本身就是稀缺的,而现有的构建流程在可控性、可追溯性和人工介入的灵活性上,都还有明显的改进空间。
MemCraft 就是沿着这个方向做出来的。它不直接来自 HEART-Bench 的代码,而是把评测过程中积累的对“什么样的数据才算好”的理解,和我对分步控制、人工审核、情境设计、人格分析等问题的思考结合在一起,重新搭了一套独立的构建流程。
它在解决什么
长篇叙事文本里的角色经历是隐含的、散落的、前后交织的。一个角色可能在第三章提到童年,在第十章回溯同一段经历,在第二十章被另一个角色用不同视角重新描述。人工整理这些内容很慢,而且很难保证一致性。
直接让 LLM 来做呢?它可以生成看起来很通顺的总结,但你很难信任它。它会编造原文里没有的细节,会把不同时间线的事件混在一起,会遗漏关键转折,而且你很难知道它到底是在“回忆”还是在“想象”。
这里的核心矛盾是:LLM 的生成能力和结构化数据的质量要求之间有落差。 弥合这个落差不能只靠更好的模型,还需要一套流程设计,让每一步产出都能被检查、被修正、被重新执行。这一点在 HEART-Bench 的数据复核阶段感受特别明显——数据质量问题往往不是单点错误,而是上游某个环节的偏差被逐步放大到下游。如果流程本身没有检查和回退的机制,问题就会一直积累到最终产出才暴露。
它是怎么工作的
整个系统围绕一条 7 步主链构建。每一步都有明确的输入和输出,中间结果全部保存,任何一步都可以单独重跑:
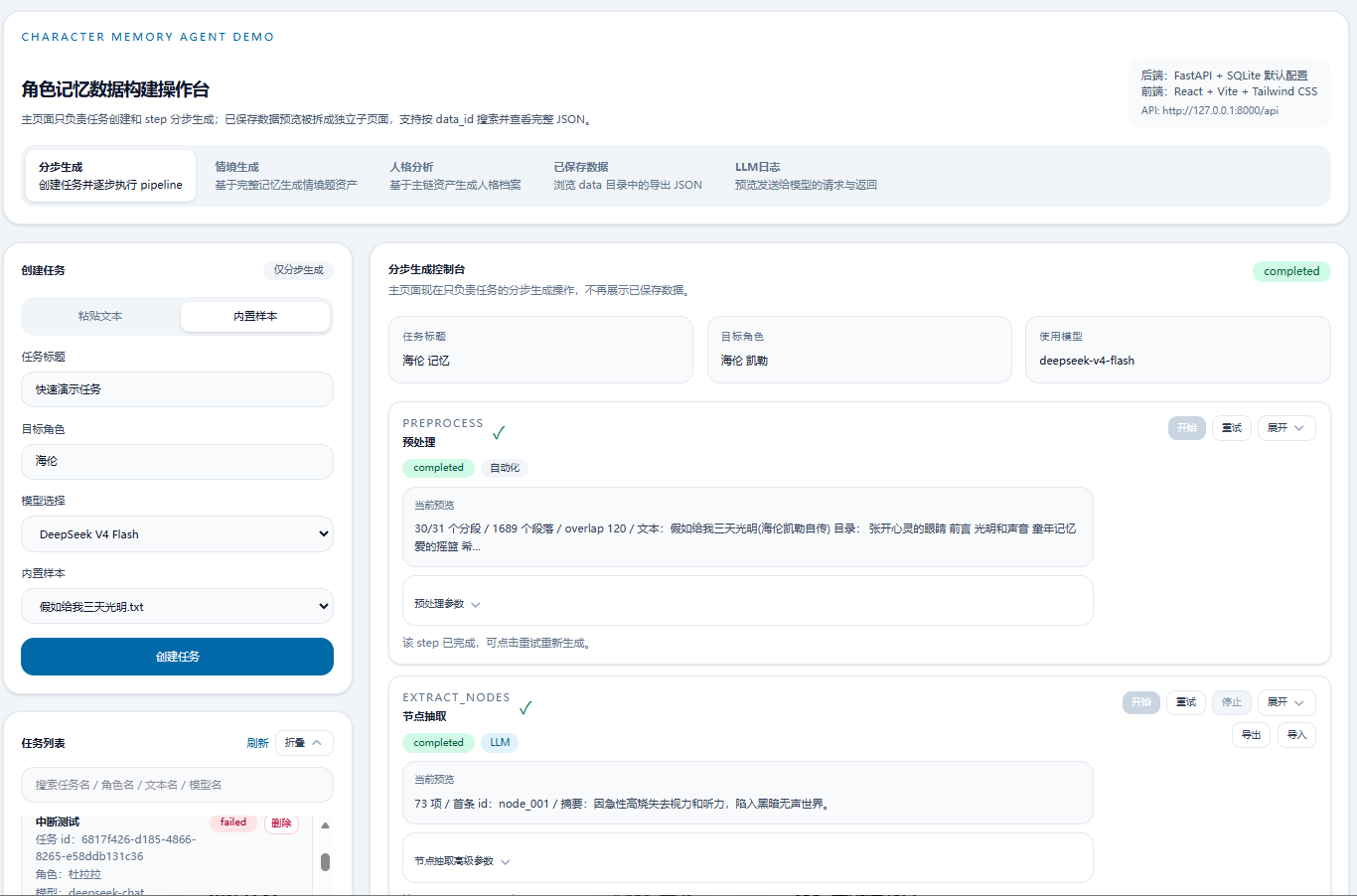
| 步骤 | 做什么 | 为什么这样设计 |
|---|---|---|
| preprocess | 按章节、场景或启发式边界将原文分块 | 让后续处理有结构可循,而不是面对一整篇长文 |
| extract_nodes | 用滑动窗口逐块抽取人生节点,再合并去重 | 窗口重叠避免遗漏跨块信息,合并避免重复 |
| review_nodes | 对节点排序、标注问题 | 不删节点,只标问题,把裁决权留给人 |
| expand_events | 将节点展开为带上下文的事件 | 节点是骨架,事件才是有血有肉的经历 |
| generate_terminology | 从事件中提取术语映射 | 统一人称和称谓,为记忆生成做准备 |
| convert_memory | 将事件转为第一人称记忆文本 | 匿名化、低主观、可直接用于 Agent 记忆 |
| final_check | 程序化检查 + LLM 逐条检查 + LLM 全局检查 | 双重校验,不信任任何单次 LLM 输出 |
主链之外,系统还支持两条分支流程:情境生成(从事件中派生情境题)和人格分析(从文本窗口中提取人格切面并综合成档案)。这两条分支的设计直接受到 HEART-Bench 的启发——在评测中我们发现,单纯的“信息召回”测试不足以衡量 Agent 的角色一致性,情境推理和人格维度的考察同样重要。分支流程复用主链的中间结果,不重复计算。
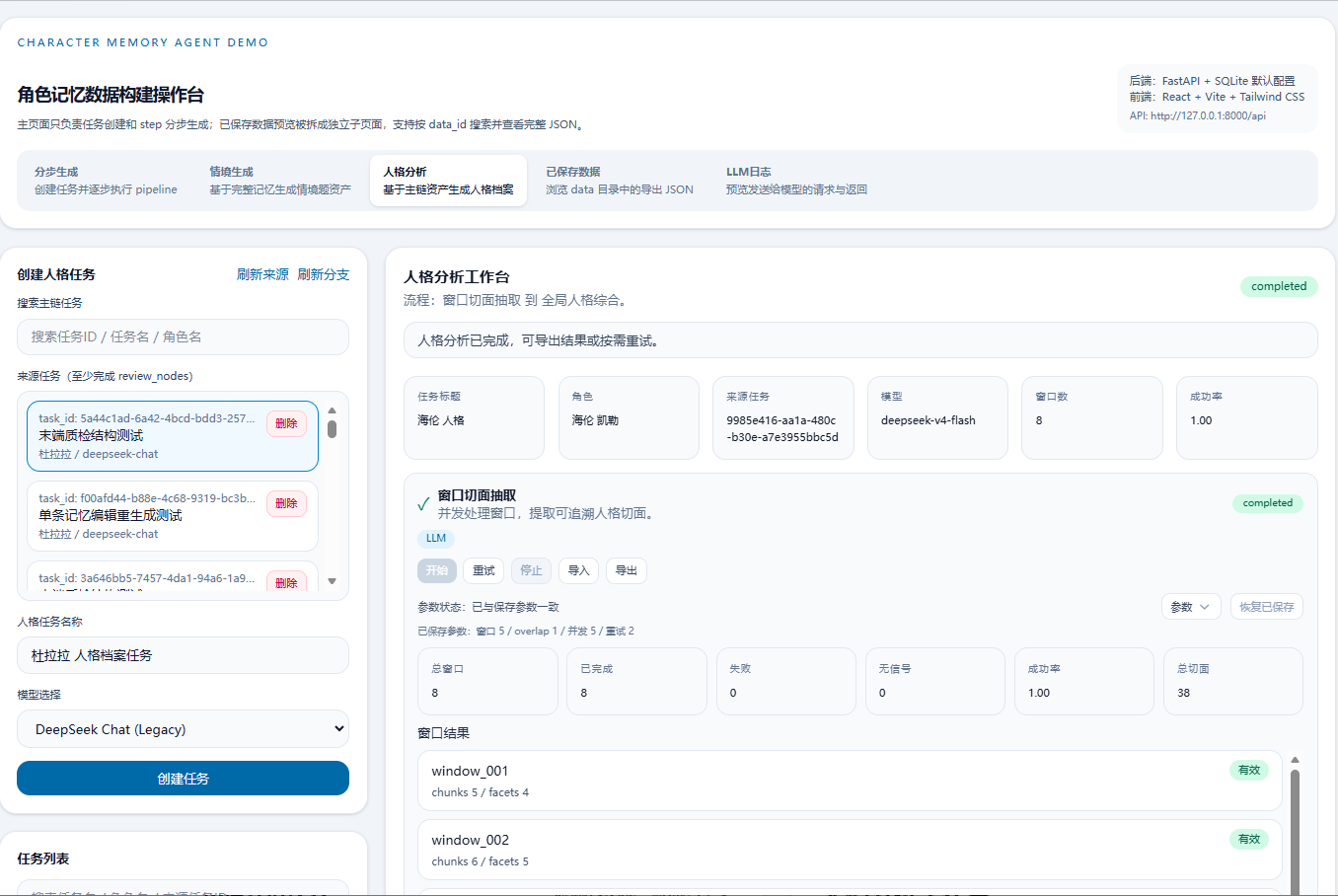
整个过程不是全自动的。每一步的结果都展示在前端工作台上,用户可以审查节点、修改术语表、重跑单个步骤、输入意见引导重新生成。系统的设计哲学是:不信任 LLM 的单次输出,但信任流程可以把它的输出逐步校正到可用。
我主要做了什么
我独立完成了这个项目从架构设计到前后端实现的全部工作。
在架构层面,我选择了分步流水线而不是端到端生成。这个决定源于 HEART-Bench 数据复核中的观察:数据质量问题往往是上游偏差的级联放大。如果把整个过程做成一步到位的黑盒,出了问题只能从头重来。分步设计的代价是代码量更多、流程更复杂,但好处是能精确定位到某一步,只重跑出问题的环节。
在 LLM 调用层面,我实现了流式请求、自动 fallback、SQLite 日志持久化和 token 估算。每一次 LLM 调用的输入输出都被完整记录,包括 prompt、response 和耗时。这让 prompt 迭代有了可回溯的依据——哪些改动带来了改善,哪些只是噪声,能从日志里看到。
在前端层面,我围绕“审查”而不是“展示”来组织页面。主链的每一步都有对应的工作台,支持查看、编辑和重跑。节点审查页展示证据片段和审核动作,术语表编辑页区分锁定行和可编辑行,最终结果页做事件和记忆的并排对照。前端整体保持低视觉噪音,把注意力留给数据本身。
在 prompt 层面,每个步骤的 system prompt 和 user prompt 都独立管理,支持版本迭代。项目里有不少 prompt 是反复修改过的——有些是因为 LLM 的输出格式不稳定,有些是因为它总会遗漏某些类型的节点,有些是因为它在处理特定文本结构时表现异常。这部分工作没有捷径,基本是跑一遍、看结果、改 prompt、再跑一遍的循环。
难点与复盘
这个项目里最难的部分,不是写代码,而是学会和 LLM 的不确定性共处。
一个具体的例子是节点抽取。早期版本用一次 LLM 调用处理整篇文本,结果要么丢失节点,要么把不同时间的事件混在一起。后来改成滑动窗口分块抽取,窗口之间有重叠,再用规则合并加 LLM 审查做去重。这个改动让召回率明显提升,但也带来了新的问题:合并逻辑有时会把两个不同的事件错误地合并成一个,因为它们的 summary 太相似了。这类问题没有一劳永逸的解法,只能在规则和 prompt 之间反复调整。
另一个至今没有完全解决的问题是长文本中的事件时间排序。LLM 对时间信息的理解是模糊的,尤其当文本里用的是“那年秋天”“几年后”“大学毕业后”这类相对时间描述时,它很难给出可靠的绝对时间线。目前系统用规则和 LLM 审查做了一层排序,但对于时间线复杂的长文本,排序结果仍然不够稳定。这可能是下一步引入 RAG 的方向——通过更精细的时间信息检索和上下文关联来辅助排序,而不是完全依赖 LLM 的推理。
还有一类问题和 prompt 工程有关。同一个 prompt 在不同的 LLM 上表现差异很大,在同一模型的不同版本上也可能不同。项目里有一个 prompt 目录专门管理各步骤的 prompt 文件,废弃的版本也会保留。这个做法让我在迭代时能更清楚地看到哪些改动带来了改善,哪些只是噪声。
当前状态
目前这个项目已经能稳定完成一条完整的链路:从文本输入到结构化记忆输出,中间每一步都可以独立执行、审查和重跑。前端支持五个页面:分步生成、情境生成、人格分析、已保存数据和 LLM 日志。数据默认保留在本地 SQLite,导出需要显式操作,不会自动写入。
它还不是一个成熟的产品,更准确地说是一个已经能工作的内部工具。很多工程细节还在继续打磨,前端的耦合度也需要进一步拆解。但它已经验证了一个核心想法:用流程来约束 LLM 的输出,比单纯依赖 prompt 来得更可靠。
最后
MemCraft 不是一个凭空想出来的项目。它从 HEART-Bench 的学术研究中获得方向,从与上交大团队的协作中看到方法,再经过自己的思考和独立实现,变成了一套能跑起来的构建流程。
从“LLM 能生成文本”到“LLM 能构建你敢用的结构化数据”,中间的距离不是模型能力的问题,而是流程设计、质量控制和人机协作的问题。这个项目让我在工程层面对这个问题有了比较完整的体验,也让我对下一步的方向——引入 RAG 改善时间排序、探索跨文档角色信息融合——有了更具体的判断。